随着以深度神经网络(DNN)为代表的AI模型的飞速发展,其在特征识别、语音处理等日常应用中被广泛应用。然而在功耗受限的边缘计算(Edge Computing)与智能物联网 (AIoT)领域中,高功耗的传统深度学习平台难以发挥其高性能的优势。这种需求引起了学术界对高能效硬件加速器研究的广泛关注,旨在减少AIoT终端片上学习与推理需要的能耗。
深度信念网络(Deep Belief Network, DBN)作为DNN模型之一,在AIoT边缘计算应用中引起了极大的关注。首先,DBN的输入和激活值均为二值数据,显着减少了模型计算量和内存大小。其次,DBN学习算法分为受限玻尔兹曼机(RBM)的局部学习。这种学习规则相比使用反向传播算法的卷积神经网络(Convolutional Neural Network, CNN)模型,在局部限制更新信号的数据流并减少外部存储器访问。此外,使用无监督学习的DBN模型非常适合边缘AIoT设备,减少了对AIoT设备中难以达到的大规模标记数据的需求。
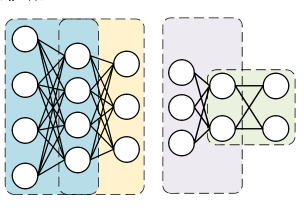
图1 一种深度学习神经网络:深度信念网络(DBN)模型
近年来,学术界设计了一些具有片上学习功能的DBN硬件加速器。这些工作集中在硬件电路的优化层次,通过利用处理单元(Processing Element, PE)的并行性,以及提出用于乘法累加(Multiply-and-Accumulate, MAC)操作的专用运算电路来加速DBN的计算流程。然而,在DBN的学习和推理阶段,学术界尚未研究和利用转置权重数据复用及神经元状态的稀疏性,来提高DBN硬件加速器的能效。因此,这些工作没有从算法层次出发,来指导架构-电路的协同设计,缺乏优化设计的全面性。
为填补DBN硬件加速器领域的这一空缺,本工作通过DBN的算法层次的分析,研究了DBN模型中的转置权重数据复用和神经元状态稀疏性,在本课题组发表于2020年IEEE亚洲固态电路大会(A-SSCC)工作的基础上[3],设计出了一种具有异构多核架构、可转置权重存储器和稀疏地址生成器的高能效DBN硬件加速器。在异构多核架构的帮助下,本工作设计的加速器实现了大规模并行的局部计算,以及将MAC运算与随机采样运算分派给不同架构的计算单元;同时,转置存储器设计的引入帮助加速器不需要额外的操作,就能完成对存储器内权重数据的转置读取;稀疏地址生成器则高效地利用了DBN模型中存在的大量0值数据,跳过了这些运算与相关数据的读取。值得一提的是,本工作第一次在DBN加速器领域引入异构多核架构以及高效的转置存储器电路,极大地提升能效与减少延迟。

图2 本工作提出的异构多核架构
本工作提出的DBN加速器在进一步进行ASIC芯片设计前,已在Xilinx Zynq FPGA上实现原型并进行了全面评估。在算法-架构-电路协同设计的帮助下,所提出的DBN处理器设计与CPU Core i7-7500实现和学术界最先进基于FPGA的帝国理工大学的设计相比,实现了×276.5和×2.25的加速。在数据稀疏性的优化的帮助下,DBN加速器以每权重更新45.0 pJ的能耗,提升了75.4%的能效,与新竹交通大学的ASIC芯片设计的能效相当。尽管本工作提出的加速器节能且具有高加速性能,但它仍然存在一些瓶颈。例如,本设计的转置存储器基于寄存器实现,而不是基于SRAM单元的高效设计,增加了额外的面积开销。此外,异构多核架构中的每个处理器核计算(workload)不平衡,导致处理器核的利用率下降。未来,本课题组将专注于在具有基于7T/8T SRAM的转置存储器设计,以及全局异步局部同步(GALS)架构中探索DBN加速器的ASIC芯片实现,以解决上述瓶颈并进一步提高加速性能和能量效率,最终将部署在智能移动机器人SoC系统级芯片上,协助智能机器人完成自主移动定位导航功能。


(d)
图3 本工作提出的转置权重存储器电路(a)及其寄存器单元(b),稀疏地址生成器电路(c),及支持转置存储的7TSRAM存储器阵列电路(d)
该工作作为本课题组在深度学习AI硬件加速器研究领域的一项初步研究成果,近期以An Energy-efficient Deep Belief Network Processor Based on Heterogeneous Multi-core Architecture with Transposable Memory and On-chip Learning [1]为题,被国际电路与系统领域高水平期刊IEEE Journal on Emerging and Selected Topics in Circuits and Systems (JETCAS)接收。该工作由国家重点研发计划智能机器人专项(2019YFB1310001)、国家自然科学基金类脑脉冲神经网络芯片项目(61974053)、中央高校基本科研基金(2019KFYXJJS049)等资助,由我院低功耗智能集成电路实验室王超老师团队集体完成。
本论文的第一作者为2017级集成电路设计与集成系统专业本科生吴加隽,通讯作者为王超研究员。吴加隽在本科三年级正式加入低功耗智能集成电路研究室。两年来,在王超和余国义两位老师的指导,以及研究室研究生同学们的帮助下,学术成果颇丰。除了在国际集成电路系统方向顶级期刊JETCAS发表的本工作以外,他还在国际集成电路系统方向顶级期刊TCAS-I发表类脑脉冲神经网络相关研究一篇[2],在IEEE集成电路四大旗舰会议之一的IEEE A-SSCC会议上发表论文一篇[3],这样的学术成绩在博士研究生中也是非常难得的。吴加隽同学在2021年获得华中科技大学优秀本科生毕业设计论文。在课题组的帮助下,加隽还在大三期间前往新加坡科技设计大学(SUTD)和珠海澳大科技研究院进行交流实习。在本科科研经历与成果的帮助下,吴加隽于2021年9月以全额奖学金进入香港大学电机电子工程系(Department of Electrical and Electronic Engineering)攻读博士学位。
[1] J. Wuet al., “An Energy-efficient Deep Belief Network Processor Based on Heterogeneous Multi-core Architecture with Transposable Memory and On-chip Learning,” inIEEE Journal on Emerging and Selected Topics in Circuits and Systems(JETCAS), early access, Sep. 27th, 2021. (影响因子:3.916)https://ieeexplore.ieee.org/document/9548916.
[2] J. Wuet al., “Efficient Design of Spiking Neural Network with STDP Learning Based on Fast CORDIC,” inIEEE Transactions on Circuits and Systems I: Regular Papers(TCAS1), vol. 68, no. 6, pp. 2522-2534, June 2021.(影响因子:3.605)https://ieeexplore.ieee.org/document/9366935.
[3] J. Wuet al., “An Energy-efficient Multi-core Restricted Boltzmann Machine Processor with On-chip Bio-plausible Learning and Reconfigurable Sparsity”, inIEEE Asian Solid State Circuit Conference(A-SSCC 2020), Nov. 2020, Hiroshima, Japan.https://ieeexplore.ieee.org/document/9336135.

